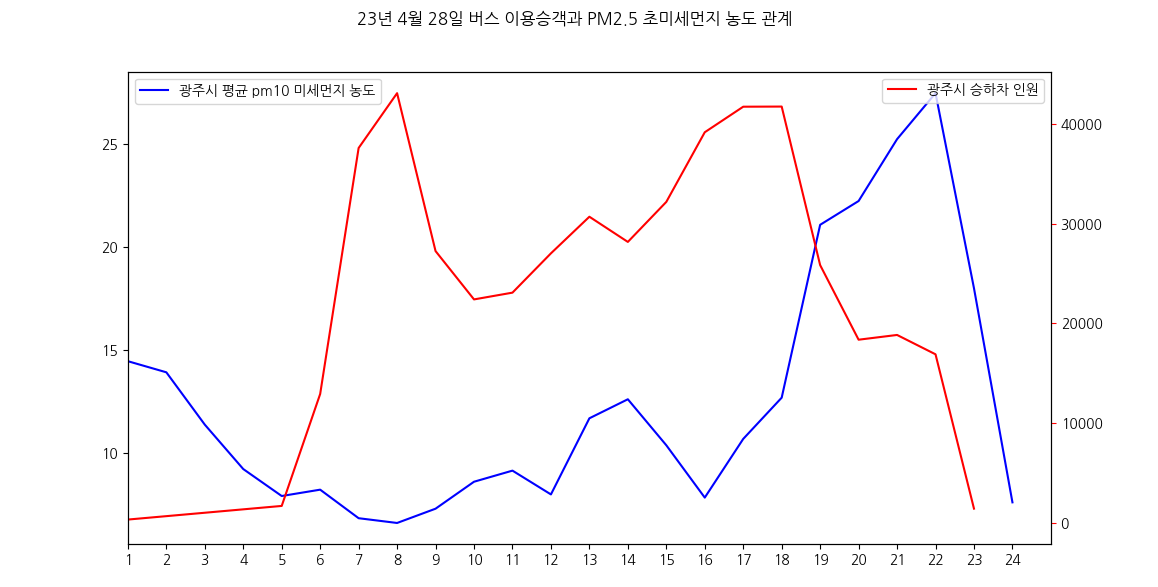
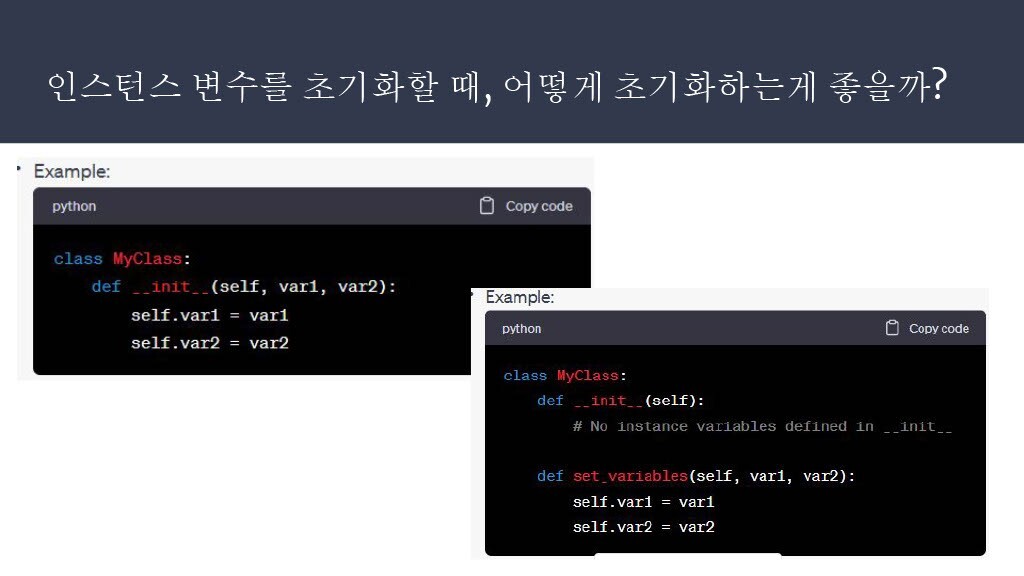
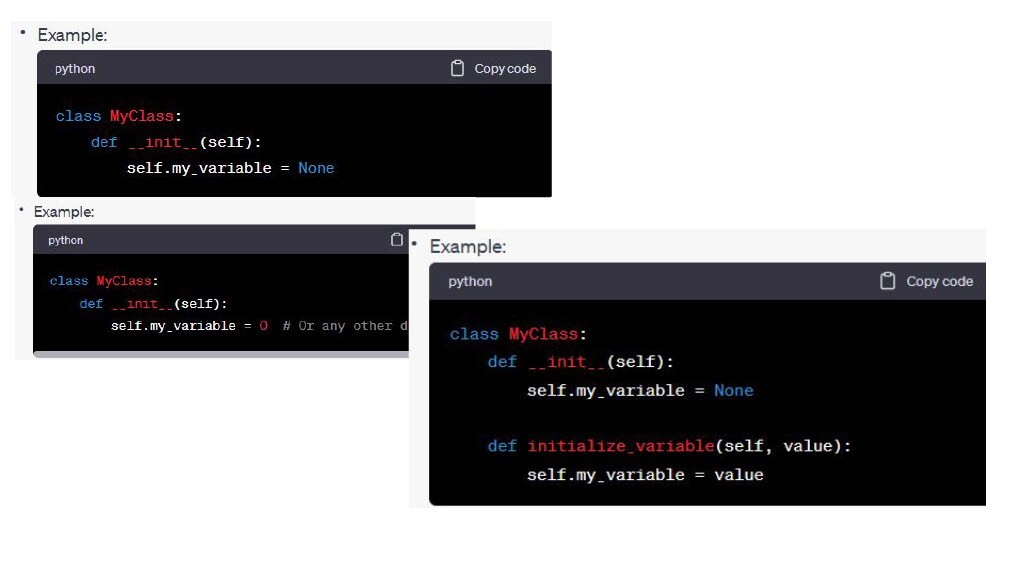
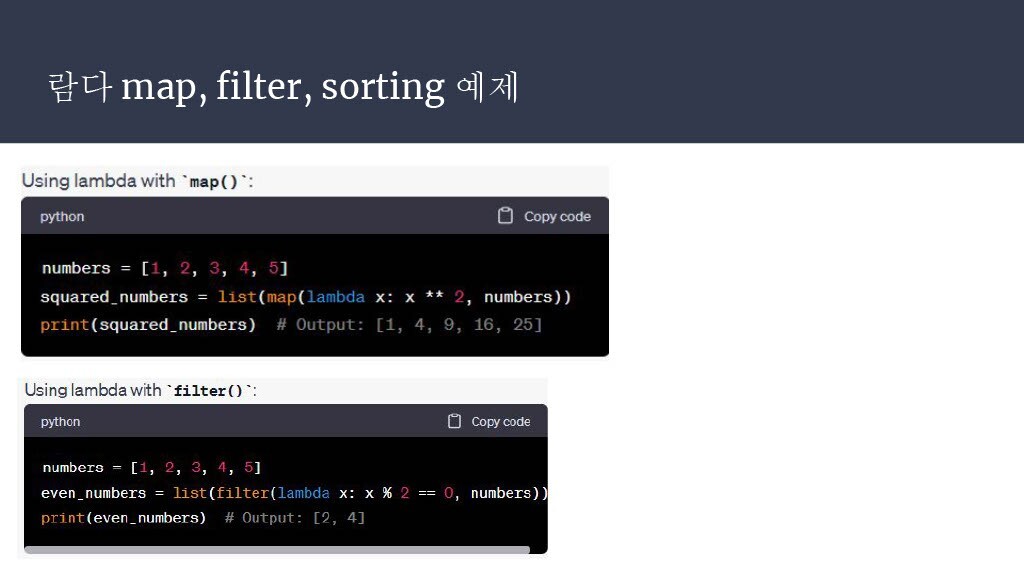
이전에도 조금씩 시각화 연습을 하고 있었기 때문에, 꾸준히 보니깐 조금씩 익숙해지는 것 같습니다.
전체 소스코드입니다.
import os
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
import matplotlib.lines
def main():
draw_violin_plots()
set_plot_title('예제19')
save_fig_png()
showing_plot()
def showing_plot():
plt.show()
# 기본 사용
def basic_using_matplotlib():
plt.plot([1, 2, 3, 4])
def basic_using_matplotlib_2():
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
def basic_using_matplotlib_3():
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')
plt.axis([0, 6, 0, 20])
def basic_using_matplotlib_4():
# 0.2 씩 간격으로 균일한 등차
t = np.arange(0., 5., 0.2)
plt.plot(t, t, 'r--', t, t ** 2, 'bs', t, t ** 3, 'g^')
# 숫자 입력하기
def input_dataset_1():
plt.plot([1, 2, 3, 4], [2, 3, 5, 10])
def input_dataset_2():
# dictionary type 사용(레이블이 있는 데이터)
data_dict = {'X축': [1, 2, 3, 4, 5], 'Y축': [2, 3, 5, 10, 8]}
plt.plot('X축', 'Y축', data=data_dict)
# 축 레이블 설정
def set_axis_label(x_label_title, y_label_title):
plt.xlabel(x_label_title)
plt.ylabel(y_label_title)
def set_axis_label_with_space(x_label_title, y_label_title):
plt.xlabel(x_label_title, labelpad=10)
plt.ylabel(y_label_title, labelpad=20)
def set_axis_label_another_position(x_label_title, y_label_title):
plt.xlabel(x_label_title, loc='right')
plt.ylabel(y_label_title, loc='top')
# 범례 표시하기
def set_legend_basic():
fig = plt.figure(1)
fig: matplotlib.pyplot.Figure
ax = fig.axes[0]
ax: matplotlib.pyplot.Axes
ax.legend(title='범례', labels=['첫번째'])
# stack example
def doing_sample():
x = np.linspace(0, 6 * np.pi, 100)
y = np.sin(x)
plt.ion()
fig = plt.figure()
ax = fig.add_subplot(111)
line1, = ax.plot(x, y, 'r-') # Returns a tuple of line objects, thus the comma
for phase in np.linspace(0, 10 * np.pi, 500):
line1.set_ydata(np.sin(x + phase))
fig.canvas.draw()
fig.canvas.flush_events()
# 선 종류 지정하기
def set_line_type():
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')
plt.plot([2, 3, 4, 5], [1, 2, 3, 4], 'bs')
# 마커 지정하기
def set_markers():
plt.plot([1, 2, 3, 4], [2, 3, 5, 10], 'bo--')
def set_markers_2():
plt.plot([4, 5, 6], marker="H")
plt.plot([3, 4, 5], marker="d")
plt.plot([2, 3, 4], marker="x")
plt.plot([1, 2, 3], marker=11)
plt.plot([0, 1, 2], marker='$Z$')
# 색상 지정하기
def set_color():
plt.plot([1, 2, 3, 4], [2, 3, 5, 10], color='#e35f62', marker='o', linestyle='--')
# 그래프 영역 채우기
def fill_sector():
x = [1, 2, 3, 4]
y = [2, 3, 5, 9]
plt.plot(x, y)
# plt.fill_between(x[1:3], y[1:3], alpha=0.5)
plt.fill_between(x[1:], y[1:], alpha=0.5)
# 축 스케일 지정
def set_axis_log_scale():
x = np.linspace(-10, 10, 1000)
y = x ** 3
plt.plot(x, y)
plt.yscale('symlog')
# 여러 곡선 그리기
# pass
# 그리드 설정하기
def set_grid_on():
# plt.grid(True)
# plt.grid(True, axis='x')
plt.grid(True, axis='y')
# 눈금 표시하기
def show_ticks():
x = np.linspace(0., 2., 100, endpoint=True)
plt.plot(x, x)
plt.plot(x, x ** 2)
plt.plot(x, x ** 3)
plt.xticks([-0.5, 0, 1, 2, 2.5], labels=['하나', '둘', '셋', '넷', '다섯'])
plt.yticks(np.arange(0, 10.5, 0.5))
# 타이틀 설정하기
def set_plot_title(title_str):
font_dict = {
'fontsize': 20,
'fontweight': 'bold'
}
# plt.title(title_str)
plt.title(title_str, fontdict=font_dict, loc='left', pad=20) # 이렇게하면 2개가 생김
# 수평선/수직선 그리기
def draw_vertical_or_horizontal_lines():
x = np.arange(0, 4.5, 0.5)
plt.plot(x, x + 1, 'bo')
plt.plot(x, x ** 2, 'g--')
plt.plot(x, -2 * x + 3, 'r:')
plt.axhline(3.0, 0.2, 1.0, color='gray', linestyle='-', linewidth=2)
plt.hlines(6.0, 1.0, 2.5, color='cyan', linestyle='solid', linewidth=3)
plt.axvline(3.0, 0.2, 1.0, color='lightblue', linestyle='-', linewidth=2)
plt.vlines(6.0, 1.0, 2.5, color='purple', linestyle='solid', linewidth=3)
# 막대 그래프 그리기
def draw_vertical_bar():
x = np.arange(4)
years = ['2020', '2021', '2022', '2023']
values = [120, 190, 230, 530]
plt.bar(x, values, color=['r', 'y', 'y', 'g'], align='edge', width=0.2, edgecolor='lightgray', tick_label=years)
# 수평 막대 그리기
def draw_horizontal_bar():
x = np.arange(5)
trial_count = ['first', 'second', 'third', 'fourth', 'fifth']
value = [17, 15, 16, 14, 12]
color_list = [get_random_color() for x in range(5)]
plt.barh(x, value, tick_label=trial_count, color=color_list)
# 산점도 그리기
def draw_scatters():
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
area = (30 * np.random.rand(n)) ** 2
# colors = np.random.rand(n)
colors = [get_random_color() for x in range(n)]
plt.scatter(x, y, s=area, c=colors)
# 3차원 산점도 그리기
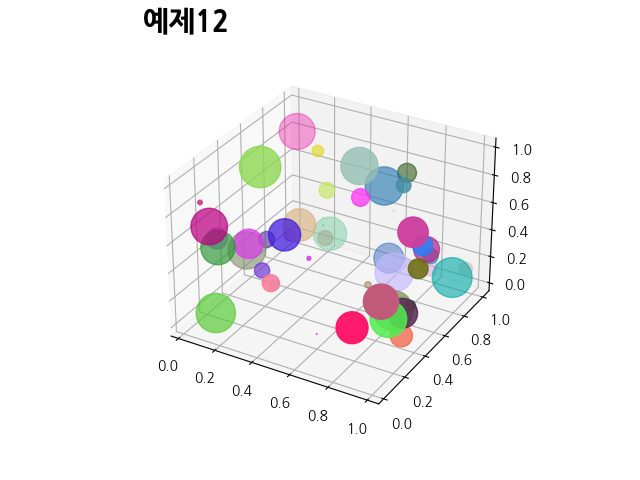
def draw_3D_scatters():
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
z = np.random.rand(n)
area = (30 * np.random.rand(n)) ** 2
colors = [get_random_color() for x in range(n)]
figure = plt.figure(1)
ax = figure.add_subplot(111, projection='3d')
ax.scatter(x, y, z, s=area, color=colors, marker='o')
# 히스토그램 그리기
def draw_histogram():
random_bwt = np.random.randint(40, 101, size=100)
figure = plt.figure(1)
ax = figure.axes[0]
counts, edges, bars = ax.hist(random_bwt, bins=10, histtype='barstacked', color=get_random_color())
plt.bar_label(bars) # 바 상단에 숫자 첨부
# 에러바 표시하기
def draw_error_bar():
x = [1, 2, 3, 4]
y = [1, 4, 9, 16]
yerr = [2.3, 3.1, 1.7, 2.5]
plt.errorbar(x, y, yerr=yerr)
# 파이 차트 그리기
def draw_pie_chart():
ratio = [34, 32, 16, 18]
labels = ['Apple', 'Banana', 'Melon', 'Grapes']
plt.pie(ratio, labels=labels, autopct='%.1f%%', startangle=260, counterclock=False)
# 히트맵 그리기
def draw_heatmap():
arr = np.random.standard_normal((30, 40))
plt.matshow(arr)
plt.colorbar(shrink=0.5, aspect=10)
# 컬러맵 설정하기
def using_colormap():
arr = np.random.standard_normal((12, 100))
plt.subplot(2, 2, 1)
plt.scatter(arr[0], arr[1], c=arr[2])
plt.spring()
plt.title('spring')
plt.subplot(2, 2, 2)
plt.scatter(arr[3], arr[4], c=arr[5])
plt.summer()
plt.title('summer')
plt.subplot(2, 2, 3)
plt.scatter(arr[6], arr[7], c=arr[8])
plt.autumn()
plt.title('autumn')
plt.subplot(2, 2, 4)
plt.scatter(arr[9], arr[10], c=arr[11])
plt.winter()
plt.title('winter')
# 이미지 저장하기
def save_fig_png():
path = r'plot_imgs/'
dir_list = os.listdir(path)
plt.savefig(path + f'saved_figure_{len(dir_list) + 1:02d}.png')
# 박스 플롯 그리기
def draw_box_plots():
data_a = np.random.normal(0, 2.0, 100)
data_b = np.random.normal(-3.0, 1.5, 500)
data_c = np.random.normal(1.2, 1.8, 1000)
fig, ax = plt.subplots()
ax: plt.Axes
ax.boxplot([data_a, data_b, data_c], notch=True, whis=2.5, vert=False)
ax.set_xlim(-10.0, 10.0)
ax.set_xlabel('Value')
ax.set_ylabel('Data Type')
# 바이올린 플롯 그리기
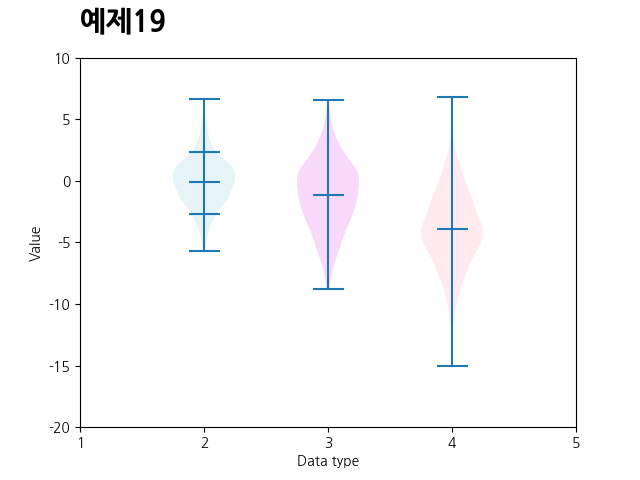
def draw_violin_plots():
data_a = np.random.normal(0, 2.0, 1000)
data_b = np.random.normal(-1.2, 3, 500)
data_c = np.random.normal(-4, 3, 2000)
fig, ax = plt.subplots()
ax: plt.Axes
violin = ax.violinplot([data_a, data_b, data_c], positions=[2, 3, 4],
showmeans=True, quantiles=[[0.1, 0.9], [], []])
ax.set_ylim(-20.0, 10.0)
ax.set_xticks([1, 2, 3, 4, 5])
ax.set_xlabel('Data type')
ax.set_ylabel('Value')
violins = violin['bodies']
violins[0].set_facecolor('lightblue')
violins[1].set_facecolor('violet')
violins[2].set_facecolor('pink')
# 다양한 패턴 채우기
def fill_pattern():
x = [1, 2, 3]
y = [1, 2, 3]
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2)
ax1: plt.Axes
ax2: plt.Axes
ax3: plt.Axes
ax4: plt.Axes
ax1.bar(x, y, color='aquamarine', edgecolor='black', hatch='/')
ax2.bar(x, y, color='salmon', edgecolor='black', hatch='\\')
ax3.bar(x, y, color='navajowhite', edgecolor='black', hatch='+')
ax4.bar(x, y, color='lightskyblue', edgecolor='black', hatch='*')
plt.tight_layout()
# numpy로 random hex code 만들기
def get_random_color():
result_color = "#"
rgb_numbers = np.random.randint(0, 256, size=3)
result_color = result_color + ''.join('{:02X}'.format(a) for a in rgb_numbers)
return result_color
if __name__ == '__main__':
main()